One of my highlights of 2022 was my paper with Dr Shahin Tavakoli being published in JRSS-C: Exploring British Accents: Modelling the Trap-Bath Split with Functional Data Analysis. Statistical applications in phonetics have fascinated me since I came across Shahin’s previous work in the area. He very kindly agreed to supervise my final year dissertation at Warwick, and later encouraged me to improve and publish the results. This was my first experience of doing research, and it was challenging and rewarding in equal (high!) measure. Here’s a brief summary of the paper.
The paper is about modelling geographic accent variation in Great Britain using speech recordings and functional data analysis. We focus on the vowel in bath which typically rhymes with trap in a Northern British accent whereas in the South it doesn’t — this is known as the ‘trap-bath split’.
Vowels can be represented as sets of smooth curves; we use both formant and MFCC representations.
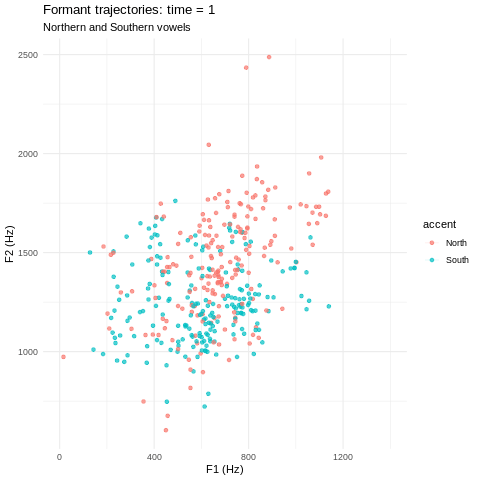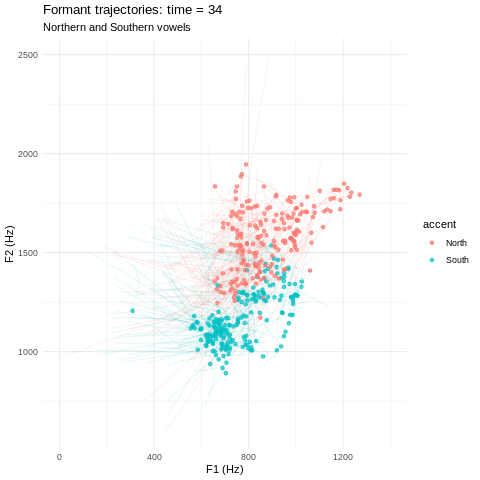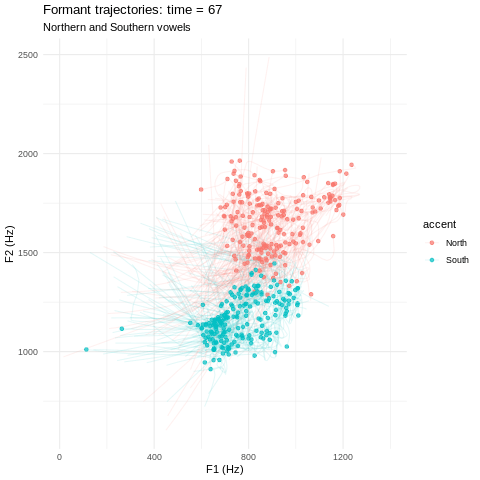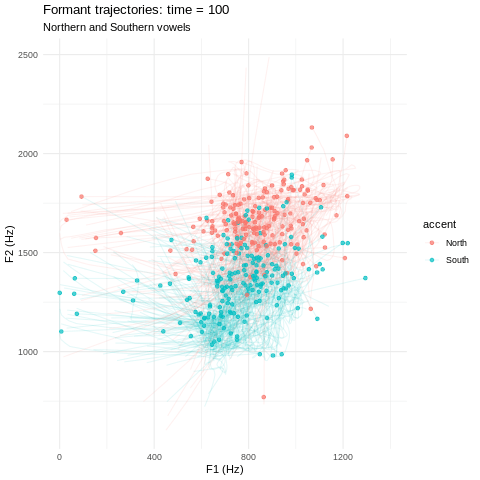
We train two separate accent classifiers on a labelled dataset of Northern & Southern bath vowels. One model uses formants and one uses MFCCs. My favourite part is where we can resynthesise vowels along a North-South ‘accent spectrum’ using functional PCA followed by logistic regression1!
Resynthesising the word blast from a Southern vowel towards a Northern vowel:
And resynthesising the word class from a Northern vowel towards a Southern vowel:
Our second dataset contains speech recordings from across GB, without accent labels (from the British National Corpus). We use it to demonstrate how predictions from the accent classifiers can help us visualise geographic variation in accents!
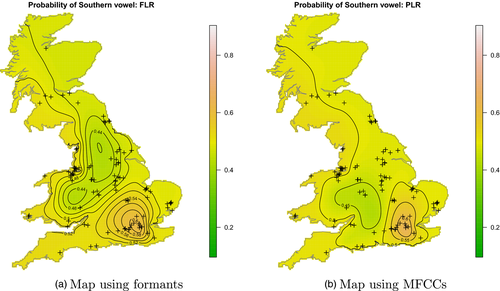
PCA and logistic regression have earned my undying respect.↩︎